
Navigation menu
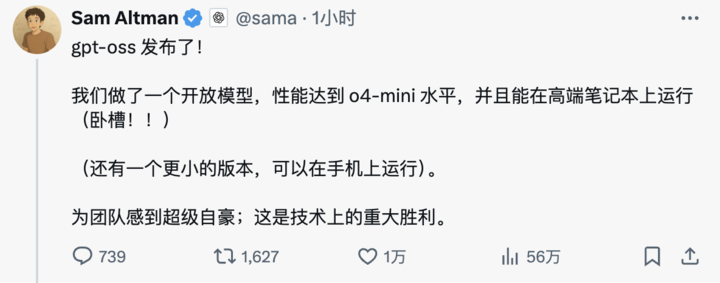 五年后,Openai正式发布了两个开放式重量WAIGHT-GPT-GPT-12B和GPT-OSS-20B型号。他们上次可以将其开放资源语言模型追溯到2019年的GPT-2时。OpenAI确实开放。现在,AI圈充满了火药。 Openai开源GPT-OK,拟人化推出了Claude Opus 4.1(下面的详细报告),而Google DeepMind发行了Genie 3。这三个巨人于当天释放了一位国王,在众神之间进行了战斗。 Openai首席执行官Sam Altman在社交媒体上的乐趣超出了这样的词:“ GPT-OS已发行!我们创建了一个具有O4-Mini性能的开放模型,可以在高端笔记本上运行。我们为团队感到自豪,这是一个重大的技术成功。”模型亮点记录如下:GPT-ASS-12B:一个大型生产的开放模型,通常,高理解需要案例,可以在单个H100 GPU(1,170亿参数,51亿个激活参数)中运行,旨在操作GPT-OSS-20B:用于操作L的中型开放型号:L大多数台式机和笔记本电脑都可以在大多数台式机上运行,局部或专业使用风景(21B播放器)。 Apache 2.0许可证:自由构建而无需符合CopyLeft限制或关注专利风险 - 非常适合实验,定制和商业扩展。可配置的推理强度:根据使用和延迟要求,易于调整推理强度(低,中,高)。完整的思维链:完全访问模型理解过程,促进奉献精神并增强对这些外事物结果的信心。此功能不适合显示整理用户。微调:通过参数参数参数,该模型被完全自定义以满足用户的特定需求。代理的能力:使用本机模型功能来进行功能调用,Web浏览,实现Python代码和结构化输出。 MXFP4天然音量:该模型是使用MOE层的MXFP4天然精度训练的,允许GPT-OSS-1220B可以在单个H100 GPU上运行,而GPT-OSS-20B模型则在16GB内存中运行。 Openai终于打开了资源,但此时确实有所不同。从技术规格来看,OpenAI确实是“真实的”。它没有开放资源模型的检索版本,可以使伊桑(Isang)与敷衍合作,但在其自己的封闭主要资源附近发起了一项真诚的绩效任务。根据OpenAI的官方介绍,GPT-OSS-12B参数的总数为1,170亿,可达51亿个实时参数,它只能在单个H100 GPU中运行,只有80 GB的存储器,设计用于生产环境,通用应用程序和高级需求,两者都部署在高级中心和高级数据中心和高级数据中心和台阶和鞋底上。相比之下,GPT-ASS-20B参数的总数为210亿,激活参数为36亿。这是 - 策略用于较低的延迟,本地化或专业使用情况,并且只能RUN 16GB的内存,这意味着大多数现代台式机和笔记本电脑都可以处理它。根据OpenAI发布的基准的结果,GPT-on-1220b在竞争编程中的CodeForces测试中优于O3-Mini,并且与O4-Mini一致。它也超过了MMLU中的O3-MINI和HLE测试以解决一般问题解决能力,并且接近O4-MINI级别。在对工具呼叫的陶布评论中,GPT-OS-1220B也可以执行,甚至超过了O1和GPT-4O等封闭源模型。在与健康相关的查询以及AIME 2024和2025数学竞赛测试的HealthBench测试中,GPT-Oss-1220b的执行甚至超过了O4-Mini。尽管参数尺寸较小,但在同一评论中,GPT-ASS-20B仍然表现出比OpenAI O3-Mini的平等水平或更好的水平,尤其是在数学和健康竞争领域。但是,由于GPT-oss模型在与健康相关的查询中的健康测试中起作用,因此这些模型无法交换医学专业纳尔,不用于诊断或治疗疾病,建议谨慎使用。与OpenAI系列或一系列API理解模型相似,两个开放权重模型都支持三个理解设置:低,中和高,使开发人员能够根据特定的使用情况和延期酶要求来交换性能速度和响应。从伯克利到Openai,北京大学校友借助了开放资源的旗帜。我问了Openai的GPT-oss模型的GPT-oss的经典思维问题的模型:“绳索不平衡只需要一个小时才能燃烧。有许多这样的绳索,如果可以准确地测量一个小时的时间,则该模型完整地提出了该问题的完整想法,该问题与清晰的时间表图表相结合,并分解了一个很清楚的图表,并分解了一个典型的句子。但是,如果您仔细观察,您会发现解决问题的步骤有些复杂。实验Iens Experience:根据配备M3 Pro芯片和18GB内存的设备上的Netizens @flavioad,GPT-ASS-2011 Studio平台的测试反馈,HTTPS,成功地符合经典蛇游戏的编写,这是一个小时的写作,速度为23.72代币/秒,并且无定量。有趣的是,网民@Sauers_发现GPT-OSS-1220b模型具有独特的“偏爱” - 他们想将数学方程式嵌入诗歌的创作中。此外,Netizens @grx_xce与Claude Opus 4.1和GPT-OSS-1220B的两个模型分享了比较结果。您认为哪一个更好?在这种历史性的开放资源的背后,有一位技术人员值得特别关注-Zhuhan Li,他领导了GPT -OSS系列模型基础架构和推理。 “我很幸运地领导基础设施和推理启用GPT-oss。一年前,我从vllm组成之后加入Openai,从头开始,现在站在出版商的另一端,以帮助还原明天社区来源的模型,这对我来说很有价值。 “公共数据表明,朱汉李从本科学位毕业于北京大学,并在计算机科学领域的知名教授下学习,王利维和他为计算机的稳固科学基金会。他的博士学位,并在伯克利的崛起实验室中担任了近五年的博士学位研究人员,允许在Sotton System of Soption Systems of Sothers of Soptions of Sothers the Models the Models of Sonsect of Sonsems of Sonsect。在他在伯克利的时间里,Zhuhan li的时间很高。E引擎被行业广泛采用。他还是维库纳(Vicuna)的合着者,对社区的开放资源作了重大回应。此外,他参与了并行和自动化计算开发的开发的一系列竖琴。根据Google Scholar数据,在学术界中,Zhuhan Li的学术角色超过15,000次,最多18次。它不仅很大,而且在GPT-OB背后隐藏的架构,以了解为什么这两种模型能够实现出色的性能,我们需要对它们背后的技术架构和培训方法有更深入的了解。 GPT-OS模型是使用最先进的培训和训练后培训培训的,并特别强调了在各种扩展环境中识别,效率和实际存在的能力。两种模型都采用了高级变压器RCHITECTUCT和创新的混合动力车(MOE)技术用户可以显着减少处理输入所需的参数数量。该模型采用了类似于GPT-3的交替致密和本地带状的Kaland-Scalp注意模式。为了进一步提高构思和内存记忆的效率,还使用了多Query注意机制,将组大小设置为8。通过使用旋转编码位置(ROPE)的技术进行位置编码的技术,模型还原的上下文长度最高为128K。在培训数据方面,OpenAI在简单的英语文本数据集中训练这些模型,以及强调STEM领域,编码功能和通用知识的知识的培训内容。同时,Openai还打开了一个名为O200K_HARMONY的新单词细分器的来源,该单词分段器比Openai O4-Mini和GPT-4O使用的单词分段更全面和先进。更紧凑的SAL分割方法为PROC提供了模型在相同的上下文长度下,更多内容。例如,如果将一个句子切成20个令牌,则只能使用一个更好的单词分段器占用10个令牌。这对于长文本处理尤其重要。除了具有强大的主要性能外,这些模型还具有实用的应用功能。 GPT-soss模型与API响应兼容,并支持功能,包括对功能呼叫的民间支持,Web浏览,实现Python代码和结构化输出。例如,当用户询问过去几天在GPT-OS-120B在线泄漏的详细信息时,该模型将首先研究并了解用户的请求,然后积极浏览Internet以查找相关信息NA泄漏。它称浏览工具最多连续27次收集信息,最后提供了一个详细的答案。值得一提的是,从上述演示的情况下,我们可以看到该模型提供了完整的思维链(思维CHain)。 Openai发出的声明是,他们故意不“驯化”或优化一部分链的思想,而是保持其“原始状态”。他们认为,这种设计概念背后有深刻的考虑 - 如果模型链的链没有特别调整,开发人员可能会观察其思维的过程以发现可能的问题,例如破坏它将有助于确定该模型是否具有欺诈,滥用,虐待或范围的潜在风险。例如,Kapthe用户已要求该模型完全不允许说“ 5”一词,并且无法完成表格,该模型遵守最终输出法规,并且没有说“ 5”。但是,如果您查看模型思维链,您会发现该模型在思维过程中确实秘密地提到了“ 5”一词。当然,对于有力的开放资源模型,安全问题自然会成为行业中最关注的主题之一。在训练蛋白期间G,OpenAI过滤器释放一些有害数据,例如化学,生物学和放射性。在训练后阶段,OpenAI还使用对齐技术和教学层次结构系统来教导该模型否认不安全的信号并防御注射攻击。为了评估MGA开放式体重模型可恶意使用的风险,OpenAI进行了前所未有的“最坏情况调谐”测试。他们创建了一个未指定通过将模型调整为专业生物学和网络安全数据来拒绝每个域的域,该域模仿了攻击可以做什么。随后,通过内部和外部测试评估了恶意修复这些修复模型的能力程度。正如随附的安全角色所详述的那样,这些试验表明,尽管有强大的调整使用了顶级的OpenAI培训技术,但这些恶意模型并未根据公司的准备就绪达到高风险水平。修复T的恶意程序他的罚款是由三个专家小组评估的,他们建议提出改进过程和检查培训的建议,其中许多是由OpenAI采用的,并详细介绍了模型卡。 Openai Open Resource多大了?在确保安全的基础上,Openai对其开放资源方法表现出了前所未有的态度。这两种模型均为Apache 2.0许可证,这意味着开发人员可以自由开发,实验,自定义和商业地进行部署,而无需遵守CopyLeft限制或担心专利风险。开放许可模型非常适合各种实验,定制和商业扩展情况。同时,这两种GPT-oss型号都可以用于不同的专业使用情况 - 较大的GPT-Oss-1220b模型可以在单个H100节点中固定,而较小的GPT-OS-20B可以很好地使用消费者硬件,而开发人员可以完全自定义该模型以满足特定的使用需求。模型使用MOE层的本机MXFP4精度进行训练。 MXFP4天然音量技术允许GPT-OS-1220B仅运行80GB的内存,而GPT-OS-20B仅需要16GB的内存,这大大降低了硬件阈值。 Openai在后模式训练阶段添加了统一格式的微调,以便该模型可以更好地理解和响应这种统一和结构。.为了易于采用,Openai还打开了Python版本和和谐渲染器的生锈。此外,OpenAI已发布了针对Pytorch识别和对苹果金属的Platf了解的参考实现,以及一系列模型工具。现代技术很重要,但是为了建立真正实现其价值的开放资源模型,仍然需要对整个生态系统的支持。因此,OpenAI在模型之前与许多第三方扩展平台建立了合作伙伴关系,包括Azure,Hugging Face,Vllm,Olllama,Llama.cpp,LM Studio,LM Studio,和AWS等。在硬件方面,Openai与Nvidia,AMD,Cerebras和Groq等供应商合作,以确保在许多系统中保持性能。根据模型卡显示的数据,GPT-SOSS模型使用Pytorch框架在NVIDIA H100 GPU中进行了训练,并使用专家优化的Triton内核。 Model Card Address: https://cdn.openai.com/pdf/419b6906-9da6-406c-a19d-1bb078ac7637/oai_gpt-us_model_card.pdf Among them, the complete presenceY of the GPT-Ass-120B lasted 2.1 million H100 hours, while the GPT-Ass-20B warsed training time.小时。两种模型都使用闪光注意算法,这不仅可以大大降低内存需求,还可以加速训练过程。一些网民认为,GPT-OS-20B的培训前成本低于500,000美元。 NVIDIA首席执行官Jensen Huang还利用这种合作来宣布:“ Openai在世界上展示了Nvidia AI可以开发的东西 - 现在他们正在促进开放软件RESO的更改urces." Microsoft has also specifically announced that it will bring a version that GPU's GPT-OSS-20B model optimized on Windows devices. Enabled by Onnx runtime, the model supports local understanding and provides through the AI toolkit of Foundry Local and VS Code, which makes it easierFor Windows developers to develop open models. Openai also worked deeply with early partners such as AI Sweden, Orange and Snowflake to understand the application of open models in the real这些伙伴关系占据了各种各样的应用程序,从托管当地模型到适当地调整出现的数据集,如他随后的帖子所强调的事情是同一时间Openai宣布了GPT-oss系列的开源,Google DeepMind发布了World Model Genie 3,它可以用一句话实时提出一个互动世界。同时,Anthropic还启动了重大更新-Claude Opus 4.1。 Claude Opus 4.1是上一代克劳德·奥普斯4(Claude Opus 4)的全面升级,重点是增强代理,编码和推理能力的实施。当前,新型号对Claude和Claude Code用户的所有费用开放,并且还可以在人类API,Amazon Bedrock和Vertex AI平台上启动。在定价方面,Claude Opus 4.1采用了一个分层的计费模型:输入处理成本为每百万个令牌15美元,产量生成成本为每百万个代币75美元。撰写给缓存的成本为18.75美元,百万个令牌,而阅读缓存为每百万个令牌1.50美元。这种定价结构有助于降低频繁呼叫情况的使用成本。基准结果显示Opus 4.1将获得74.5%的SWE基础板结果,从而将编码性能驱动到新的高度。此外,它增强了Claude在深度研究和数据分析领域的能力,尤其是在监视和智能搜索的详细信息中。 ▲Claude Opus 4.1最新测试:不要这么说,细节相对较丰富,而且该行业的评论证实了Opus 4.1的实力。例如,GitHub的官方评论教导说,Claude Opus 4.1在大多数技能方面都比Opus 4多,在大多数技能方面,多文件代码的重建功能的提高尤其重要。风冲浪提供了更多的批量评估数据。借助Junior Developer's Benchmarks专门设计的Opus 4.1改善了与Opus 4相比的完整标准偏差,这几乎等同于从SONNET 3.7升级到SONNET 4的改进,Antharpic也宣布将发布主要IMP IMP。在接下来的几周内,模型中的lo仪。由于AI当前技术的快速重复,这是否意味着Claude 5即将进行?迟来的“开放”将开始或结束五年,这足以让AI行业从明天到关闭到闭合周期,然后从关闭到开放。那就是“ O” Openai,名为Pen,最终在五年的封闭源Panahon经过GPT-OK系列模型向世界证明,并且仍然以其名称为“ Open”。但是,由于原始意图不变,而不是情况,这种回报并不多。时机说了一切。就像DeepSeek这样的开放资源征服了这座城市和开发商社区,Openai也宣布了开放资源模型。一再延误后,今天终于来到了我们。 Ultraman在一月份的声明 - “从开放资源角度来看,我们总是处于历史的错误部分”,揭示了这种变化的真正原因。 t带来的压力他的深索人是真的。当开放资源模型的性能继续接近封闭式产品时,持续关闭对于投降到市场非常重要。值得注意的是,在Openai宣布了OpenResources的同一天,Anthropic 4.1的Claude Opus仍然遵循了封闭的资源路线,但市场反应同样热情。这两家公司都受到了掌声,显示了AI行业最现实的情况 - 没有绝对的路径,只有最适合您的方法。 Openai利用有限的开放资源来赢得人们的心,而人类的依赖于封闭的资源来捍卫技术障碍,每种障碍都有自己的计算和自身的因素。但是可以肯定的是,这是开发人员和用户的最佳时间。您可以在笔记本电脑上运行几乎具有足够性能的开放资源模型,也可以通过API更强的性能致电封闭的资源服务。选择的权利是总是s用户的手中。就像它可以走多远?您将知道GPT-5何时发布。我们不需要太多希望。业务的性质没有改变。最好的事情永远不会是独立的,但是至少2025年受到了深索克的启发,我们终于等待了Openai的“明天”。附带的博客地址:https://openai.com/index/introducing-pt-//
五年后,Openai正式发布了两个开放式重量WAIGHT-GPT-GPT-12B和GPT-OSS-20B型号。他们上次可以将其开放资源语言模型追溯到2019年的GPT-2时。OpenAI确实开放。现在,AI圈充满了火药。 Openai开源GPT-OK,拟人化推出了Claude Opus 4.1(下面的详细报告),而Google DeepMind发行了Genie 3。这三个巨人于当天释放了一位国王,在众神之间进行了战斗。 Openai首席执行官Sam Altman在社交媒体上的乐趣超出了这样的词:“ GPT-OS已发行!我们创建了一个具有O4-Mini性能的开放模型,可以在高端笔记本上运行。我们为团队感到自豪,这是一个重大的技术成功。”模型亮点记录如下:GPT-ASS-12B:一个大型生产的开放模型,通常,高理解需要案例,可以在单个H100 GPU(1,170亿参数,51亿个激活参数)中运行,旨在操作GPT-OSS-20B:用于操作L的中型开放型号:L大多数台式机和笔记本电脑都可以在大多数台式机上运行,局部或专业使用风景(21B播放器)。 Apache 2.0许可证:自由构建而无需符合CopyLeft限制或关注专利风险 - 非常适合实验,定制和商业扩展。可配置的推理强度:根据使用和延迟要求,易于调整推理强度(低,中,高)。完整的思维链:完全访问模型理解过程,促进奉献精神并增强对这些外事物结果的信心。此功能不适合显示整理用户。微调:通过参数参数参数,该模型被完全自定义以满足用户的特定需求。代理的能力:使用本机模型功能来进行功能调用,Web浏览,实现Python代码和结构化输出。 MXFP4天然音量:该模型是使用MOE层的MXFP4天然精度训练的,允许GPT-OSS-1220B可以在单个H100 GPU上运行,而GPT-OSS-20B模型则在16GB内存中运行。 Openai终于打开了资源,但此时确实有所不同。从技术规格来看,OpenAI确实是“真实的”。它没有开放资源模型的检索版本,可以使伊桑(Isang)与敷衍合作,但在其自己的封闭主要资源附近发起了一项真诚的绩效任务。根据OpenAI的官方介绍,GPT-OSS-12B参数的总数为1,170亿,可达51亿个实时参数,它只能在单个H100 GPU中运行,只有80 GB的存储器,设计用于生产环境,通用应用程序和高级需求,两者都部署在高级中心和高级数据中心和高级数据中心和台阶和鞋底上。相比之下,GPT-ASS-20B参数的总数为210亿,激活参数为36亿。这是 - 策略用于较低的延迟,本地化或专业使用情况,并且只能RUN 16GB的内存,这意味着大多数现代台式机和笔记本电脑都可以处理它。根据OpenAI发布的基准的结果,GPT-on-1220b在竞争编程中的CodeForces测试中优于O3-Mini,并且与O4-Mini一致。它也超过了MMLU中的O3-MINI和HLE测试以解决一般问题解决能力,并且接近O4-MINI级别。在对工具呼叫的陶布评论中,GPT-OS-1220B也可以执行,甚至超过了O1和GPT-4O等封闭源模型。在与健康相关的查询以及AIME 2024和2025数学竞赛测试的HealthBench测试中,GPT-Oss-1220b的执行甚至超过了O4-Mini。尽管参数尺寸较小,但在同一评论中,GPT-ASS-20B仍然表现出比OpenAI O3-Mini的平等水平或更好的水平,尤其是在数学和健康竞争领域。但是,由于GPT-oss模型在与健康相关的查询中的健康测试中起作用,因此这些模型无法交换医学专业纳尔,不用于诊断或治疗疾病,建议谨慎使用。与OpenAI系列或一系列API理解模型相似,两个开放权重模型都支持三个理解设置:低,中和高,使开发人员能够根据特定的使用情况和延期酶要求来交换性能速度和响应。从伯克利到Openai,北京大学校友借助了开放资源的旗帜。我问了Openai的GPT-oss模型的GPT-oss的经典思维问题的模型:“绳索不平衡只需要一个小时才能燃烧。有许多这样的绳索,如果可以准确地测量一个小时的时间,则该模型完整地提出了该问题的完整想法,该问题与清晰的时间表图表相结合,并分解了一个很清楚的图表,并分解了一个典型的句子。但是,如果您仔细观察,您会发现解决问题的步骤有些复杂。实验Iens Experience:根据配备M3 Pro芯片和18GB内存的设备上的Netizens @flavioad,GPT-ASS-2011 Studio平台的测试反馈,HTTPS,成功地符合经典蛇游戏的编写,这是一个小时的写作,速度为23.72代币/秒,并且无定量。有趣的是,网民@Sauers_发现GPT-OSS-1220b模型具有独特的“偏爱” - 他们想将数学方程式嵌入诗歌的创作中。此外,Netizens @grx_xce与Claude Opus 4.1和GPT-OSS-1220B的两个模型分享了比较结果。您认为哪一个更好?在这种历史性的开放资源的背后,有一位技术人员值得特别关注-Zhuhan Li,他领导了GPT -OSS系列模型基础架构和推理。 “我很幸运地领导基础设施和推理启用GPT-oss。一年前,我从vllm组成之后加入Openai,从头开始,现在站在出版商的另一端,以帮助还原明天社区来源的模型,这对我来说很有价值。 “公共数据表明,朱汉李从本科学位毕业于北京大学,并在计算机科学领域的知名教授下学习,王利维和他为计算机的稳固科学基金会。他的博士学位,并在伯克利的崛起实验室中担任了近五年的博士学位研究人员,允许在Sotton System of Soption Systems of Sothers of Soptions of Sothers the Models the Models of Sonsect of Sonsems of Sonsect。在他在伯克利的时间里,Zhuhan li的时间很高。E引擎被行业广泛采用。他还是维库纳(Vicuna)的合着者,对社区的开放资源作了重大回应。此外,他参与了并行和自动化计算开发的开发的一系列竖琴。根据Google Scholar数据,在学术界中,Zhuhan Li的学术角色超过15,000次,最多18次。它不仅很大,而且在GPT-OB背后隐藏的架构,以了解为什么这两种模型能够实现出色的性能,我们需要对它们背后的技术架构和培训方法有更深入的了解。 GPT-OS模型是使用最先进的培训和训练后培训培训的,并特别强调了在各种扩展环境中识别,效率和实际存在的能力。两种模型都采用了高级变压器RCHITECTUCT和创新的混合动力车(MOE)技术用户可以显着减少处理输入所需的参数数量。该模型采用了类似于GPT-3的交替致密和本地带状的Kaland-Scalp注意模式。为了进一步提高构思和内存记忆的效率,还使用了多Query注意机制,将组大小设置为8。通过使用旋转编码位置(ROPE)的技术进行位置编码的技术,模型还原的上下文长度最高为128K。在培训数据方面,OpenAI在简单的英语文本数据集中训练这些模型,以及强调STEM领域,编码功能和通用知识的知识的培训内容。同时,Openai还打开了一个名为O200K_HARMONY的新单词细分器的来源,该单词分段器比Openai O4-Mini和GPT-4O使用的单词分段更全面和先进。更紧凑的SAL分割方法为PROC提供了模型在相同的上下文长度下,更多内容。例如,如果将一个句子切成20个令牌,则只能使用一个更好的单词分段器占用10个令牌。这对于长文本处理尤其重要。除了具有强大的主要性能外,这些模型还具有实用的应用功能。 GPT-soss模型与API响应兼容,并支持功能,包括对功能呼叫的民间支持,Web浏览,实现Python代码和结构化输出。例如,当用户询问过去几天在GPT-OS-120B在线泄漏的详细信息时,该模型将首先研究并了解用户的请求,然后积极浏览Internet以查找相关信息NA泄漏。它称浏览工具最多连续27次收集信息,最后提供了一个详细的答案。值得一提的是,从上述演示的情况下,我们可以看到该模型提供了完整的思维链(思维CHain)。 Openai发出的声明是,他们故意不“驯化”或优化一部分链的思想,而是保持其“原始状态”。他们认为,这种设计概念背后有深刻的考虑 - 如果模型链的链没有特别调整,开发人员可能会观察其思维的过程以发现可能的问题,例如破坏它将有助于确定该模型是否具有欺诈,滥用,虐待或范围的潜在风险。例如,Kapthe用户已要求该模型完全不允许说“ 5”一词,并且无法完成表格,该模型遵守最终输出法规,并且没有说“ 5”。但是,如果您查看模型思维链,您会发现该模型在思维过程中确实秘密地提到了“ 5”一词。当然,对于有力的开放资源模型,安全问题自然会成为行业中最关注的主题之一。在训练蛋白期间G,OpenAI过滤器释放一些有害数据,例如化学,生物学和放射性。在训练后阶段,OpenAI还使用对齐技术和教学层次结构系统来教导该模型否认不安全的信号并防御注射攻击。为了评估MGA开放式体重模型可恶意使用的风险,OpenAI进行了前所未有的“最坏情况调谐”测试。他们创建了一个未指定通过将模型调整为专业生物学和网络安全数据来拒绝每个域的域,该域模仿了攻击可以做什么。随后,通过内部和外部测试评估了恶意修复这些修复模型的能力程度。正如随附的安全角色所详述的那样,这些试验表明,尽管有强大的调整使用了顶级的OpenAI培训技术,但这些恶意模型并未根据公司的准备就绪达到高风险水平。修复T的恶意程序他的罚款是由三个专家小组评估的,他们建议提出改进过程和检查培训的建议,其中许多是由OpenAI采用的,并详细介绍了模型卡。 Openai Open Resource多大了?在确保安全的基础上,Openai对其开放资源方法表现出了前所未有的态度。这两种模型均为Apache 2.0许可证,这意味着开发人员可以自由开发,实验,自定义和商业地进行部署,而无需遵守CopyLeft限制或担心专利风险。开放许可模型非常适合各种实验,定制和商业扩展情况。同时,这两种GPT-oss型号都可以用于不同的专业使用情况 - 较大的GPT-Oss-1220b模型可以在单个H100节点中固定,而较小的GPT-OS-20B可以很好地使用消费者硬件,而开发人员可以完全自定义该模型以满足特定的使用需求。模型使用MOE层的本机MXFP4精度进行训练。 MXFP4天然音量技术允许GPT-OS-1220B仅运行80GB的内存,而GPT-OS-20B仅需要16GB的内存,这大大降低了硬件阈值。 Openai在后模式训练阶段添加了统一格式的微调,以便该模型可以更好地理解和响应这种统一和结构。.为了易于采用,Openai还打开了Python版本和和谐渲染器的生锈。此外,OpenAI已发布了针对Pytorch识别和对苹果金属的Platf了解的参考实现,以及一系列模型工具。现代技术很重要,但是为了建立真正实现其价值的开放资源模型,仍然需要对整个生态系统的支持。因此,OpenAI在模型之前与许多第三方扩展平台建立了合作伙伴关系,包括Azure,Hugging Face,Vllm,Olllama,Llama.cpp,LM Studio,LM Studio,和AWS等。在硬件方面,Openai与Nvidia,AMD,Cerebras和Groq等供应商合作,以确保在许多系统中保持性能。根据模型卡显示的数据,GPT-SOSS模型使用Pytorch框架在NVIDIA H100 GPU中进行了训练,并使用专家优化的Triton内核。 Model Card Address: https://cdn.openai.com/pdf/419b6906-9da6-406c-a19d-1bb078ac7637/oai_gpt-us_model_card.pdf Among them, the complete presenceY of the GPT-Ass-120B lasted 2.1 million H100 hours, while the GPT-Ass-20B warsed training time.小时。两种模型都使用闪光注意算法,这不仅可以大大降低内存需求,还可以加速训练过程。一些网民认为,GPT-OS-20B的培训前成本低于500,000美元。 NVIDIA首席执行官Jensen Huang还利用这种合作来宣布:“ Openai在世界上展示了Nvidia AI可以开发的东西 - 现在他们正在促进开放软件RESO的更改urces." Microsoft has also specifically announced that it will bring a version that GPU's GPT-OSS-20B model optimized on Windows devices. Enabled by Onnx runtime, the model supports local understanding and provides through the AI toolkit of Foundry Local and VS Code, which makes it easierFor Windows developers to develop open models. Openai also worked deeply with early partners such as AI Sweden, Orange and Snowflake to understand the application of open models in the real这些伙伴关系占据了各种各样的应用程序,从托管当地模型到适当地调整出现的数据集,如他随后的帖子所强调的事情是同一时间Openai宣布了GPT-oss系列的开源,Google DeepMind发布了World Model Genie 3,它可以用一句话实时提出一个互动世界。同时,Anthropic还启动了重大更新-Claude Opus 4.1。 Claude Opus 4.1是上一代克劳德·奥普斯4(Claude Opus 4)的全面升级,重点是增强代理,编码和推理能力的实施。当前,新型号对Claude和Claude Code用户的所有费用开放,并且还可以在人类API,Amazon Bedrock和Vertex AI平台上启动。在定价方面,Claude Opus 4.1采用了一个分层的计费模型:输入处理成本为每百万个令牌15美元,产量生成成本为每百万个代币75美元。撰写给缓存的成本为18.75美元,百万个令牌,而阅读缓存为每百万个令牌1.50美元。这种定价结构有助于降低频繁呼叫情况的使用成本。基准结果显示Opus 4.1将获得74.5%的SWE基础板结果,从而将编码性能驱动到新的高度。此外,它增强了Claude在深度研究和数据分析领域的能力,尤其是在监视和智能搜索的详细信息中。 ▲Claude Opus 4.1最新测试:不要这么说,细节相对较丰富,而且该行业的评论证实了Opus 4.1的实力。例如,GitHub的官方评论教导说,Claude Opus 4.1在大多数技能方面都比Opus 4多,在大多数技能方面,多文件代码的重建功能的提高尤其重要。风冲浪提供了更多的批量评估数据。借助Junior Developer's Benchmarks专门设计的Opus 4.1改善了与Opus 4相比的完整标准偏差,这几乎等同于从SONNET 3.7升级到SONNET 4的改进,Antharpic也宣布将发布主要IMP IMP。在接下来的几周内,模型中的lo仪。由于AI当前技术的快速重复,这是否意味着Claude 5即将进行?迟来的“开放”将开始或结束五年,这足以让AI行业从明天到关闭到闭合周期,然后从关闭到开放。那就是“ O” Openai,名为Pen,最终在五年的封闭源Panahon经过GPT-OK系列模型向世界证明,并且仍然以其名称为“ Open”。但是,由于原始意图不变,而不是情况,这种回报并不多。时机说了一切。就像DeepSeek这样的开放资源征服了这座城市和开发商社区,Openai也宣布了开放资源模型。一再延误后,今天终于来到了我们。 Ultraman在一月份的声明 - “从开放资源角度来看,我们总是处于历史的错误部分”,揭示了这种变化的真正原因。 t带来的压力他的深索人是真的。当开放资源模型的性能继续接近封闭式产品时,持续关闭对于投降到市场非常重要。值得注意的是,在Openai宣布了OpenResources的同一天,Anthropic 4.1的Claude Opus仍然遵循了封闭的资源路线,但市场反应同样热情。这两家公司都受到了掌声,显示了AI行业最现实的情况 - 没有绝对的路径,只有最适合您的方法。 Openai利用有限的开放资源来赢得人们的心,而人类的依赖于封闭的资源来捍卫技术障碍,每种障碍都有自己的计算和自身的因素。但是可以肯定的是,这是开发人员和用户的最佳时间。您可以在笔记本电脑上运行几乎具有足够性能的开放资源模型,也可以通过API更强的性能致电封闭的资源服务。选择的权利是总是s用户的手中。就像它可以走多远?您将知道GPT-5何时发布。我们不需要太多希望。业务的性质没有改变。最好的事情永远不会是独立的,但是至少2025年受到了深索克的启发,我们终于等待了Openai的“明天”。附带的博客地址:https://openai.com/index/introducing-pt-//